Request Demo
What is the mechanism of 2LXFS?
18 July 2024
2LXFS, also known as Two-Level Cross-Factor Search, is a sophisticated algorithm employed in various computational fields to enhance search efficiency and accuracy. The mechanism of 2LXFS revolves around breaking down a complex search problem into more manageable sub-problems and utilizing cross-referencing techniques to optimize the search process. Here, we delve into the detailed workings of the 2LXFS mechanism.
At its core, 2LXFS operates on the principle of multi-level hierarchy. The search space is divided into two primary levels: the upper level and the lower level. Each level has distinct roles and responsibilities in the search process.
The upper level is responsible for the broad categorization of data. It segregates the entire search space into multiple segments or clusters based on predefined criteria. This clustering is typically achieved through techniques like k-means clustering, hierarchical clustering, or other data partitioning methods. The aim here is to group similar data points together, thereby reducing the overall search space that needs to be examined in detail.
Once the upper level has divided the search space into clusters, the lower level comes into play. This level conducts a more granular search within each cluster. The lower level utilizes cross-factor search techniques to examine the interrelationships between various data points within a cluster. Cross-factor search involves analyzing multiple factors or dimensions simultaneously, which helps in identifying the most relevant data points quickly and accurately.
An essential aspect of 2LXFS is its iterative nature. The algorithm iterates between the upper and lower levels, refining the search space with each iteration. Initially, the upper level performs a broad classification, and the lower level carries out a detailed search within each cluster. Based on the results, the upper level may re-adjust the clusters, and the process repeats. This iterative refinement ensures that the search becomes progressively more accurate and efficient.
Furthermore, 2LXFS incorporates adaptive learning mechanisms. As the algorithm processes more data, it learns from previous iterations and adjusts its clustering and cross-referencing strategies accordingly. This adaptive learning capability enables 2LXFS to handle dynamic and evolving data sets effectively.
Another key feature of 2LXFS is its parallel processing capability. By dividing the search space into clusters, the algorithm can distribute the search tasks across multiple processors or computing nodes. This parallelism significantly accelerates the search process, making 2LXFS an ideal choice for large-scale data sets and real-time applications.
In summary, the mechanism of 2LXFS can be understood as a hierarchical, iterative, and adaptive search process that leverages both broad categorization and detailed cross-referencing to enhance search efficiency and accuracy. By breaking down a complex search problem into manageable sub-problems and iteratively refining the search space, 2LXFS ensures optimal search performance in various computational domains.
At its core, 2LXFS operates on the principle of multi-level hierarchy. The search space is divided into two primary levels: the upper level and the lower level. Each level has distinct roles and responsibilities in the search process.
The upper level is responsible for the broad categorization of data. It segregates the entire search space into multiple segments or clusters based on predefined criteria. This clustering is typically achieved through techniques like k-means clustering, hierarchical clustering, or other data partitioning methods. The aim here is to group similar data points together, thereby reducing the overall search space that needs to be examined in detail.
Once the upper level has divided the search space into clusters, the lower level comes into play. This level conducts a more granular search within each cluster. The lower level utilizes cross-factor search techniques to examine the interrelationships between various data points within a cluster. Cross-factor search involves analyzing multiple factors or dimensions simultaneously, which helps in identifying the most relevant data points quickly and accurately.
An essential aspect of 2LXFS is its iterative nature. The algorithm iterates between the upper and lower levels, refining the search space with each iteration. Initially, the upper level performs a broad classification, and the lower level carries out a detailed search within each cluster. Based on the results, the upper level may re-adjust the clusters, and the process repeats. This iterative refinement ensures that the search becomes progressively more accurate and efficient.
Furthermore, 2LXFS incorporates adaptive learning mechanisms. As the algorithm processes more data, it learns from previous iterations and adjusts its clustering and cross-referencing strategies accordingly. This adaptive learning capability enables 2LXFS to handle dynamic and evolving data sets effectively.
Another key feature of 2LXFS is its parallel processing capability. By dividing the search space into clusters, the algorithm can distribute the search tasks across multiple processors or computing nodes. This parallelism significantly accelerates the search process, making 2LXFS an ideal choice for large-scale data sets and real-time applications.
In summary, the mechanism of 2LXFS can be understood as a hierarchical, iterative, and adaptive search process that leverages both broad categorization and detailed cross-referencing to enhance search efficiency and accuracy. By breaking down a complex search problem into manageable sub-problems and iteratively refining the search space, 2LXFS ensures optimal search performance in various computational domains.
How to obtain the latest development progress of all drugs?
In the Synapse database, you can stay updated on the latest research and development advances of all drugs. This service is accessible anytime and anywhere, with updates available daily or weekly. Use the "Set Alert" function to stay informed. Click on the image below to embark on a brand new journey of drug discovery!
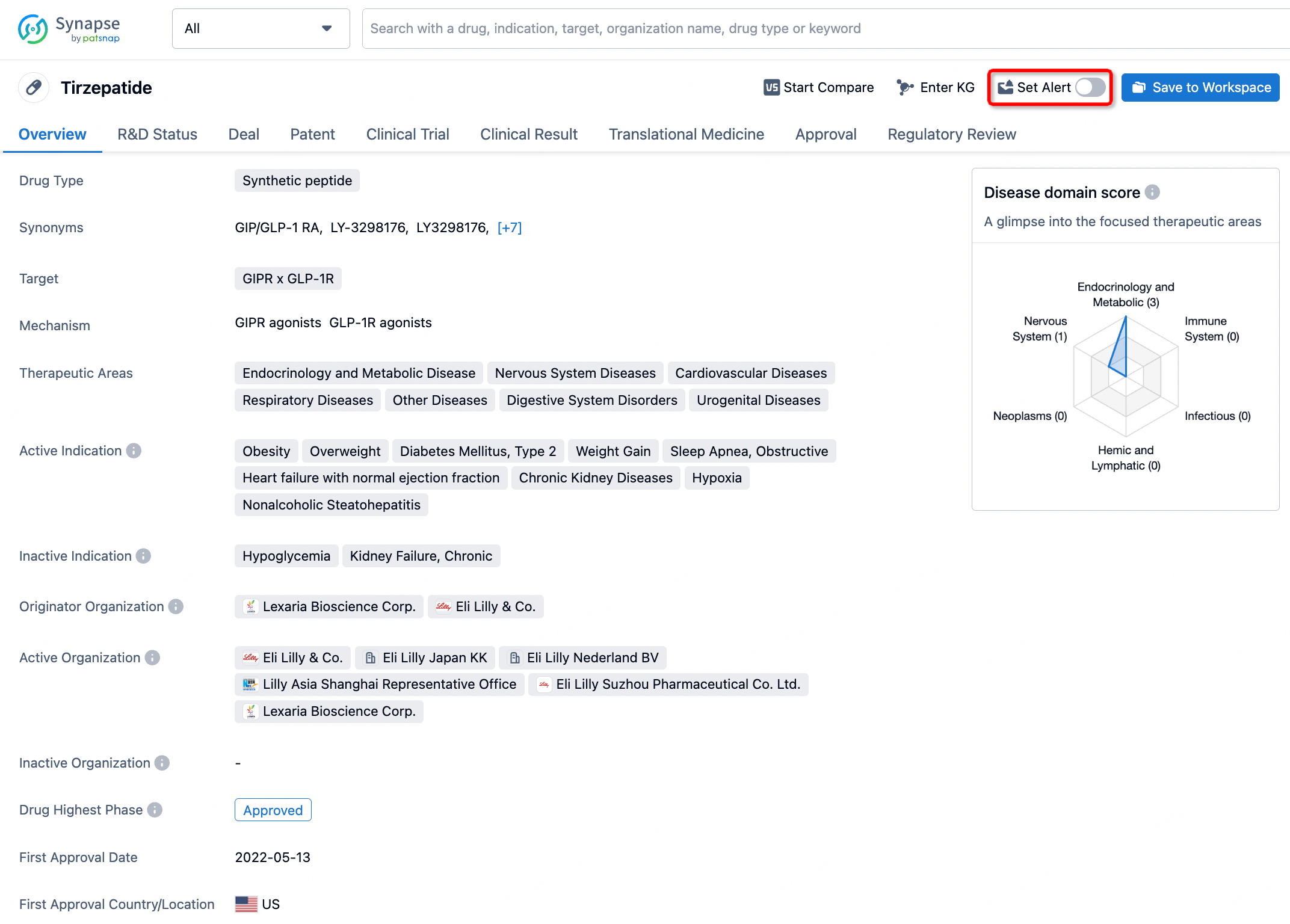
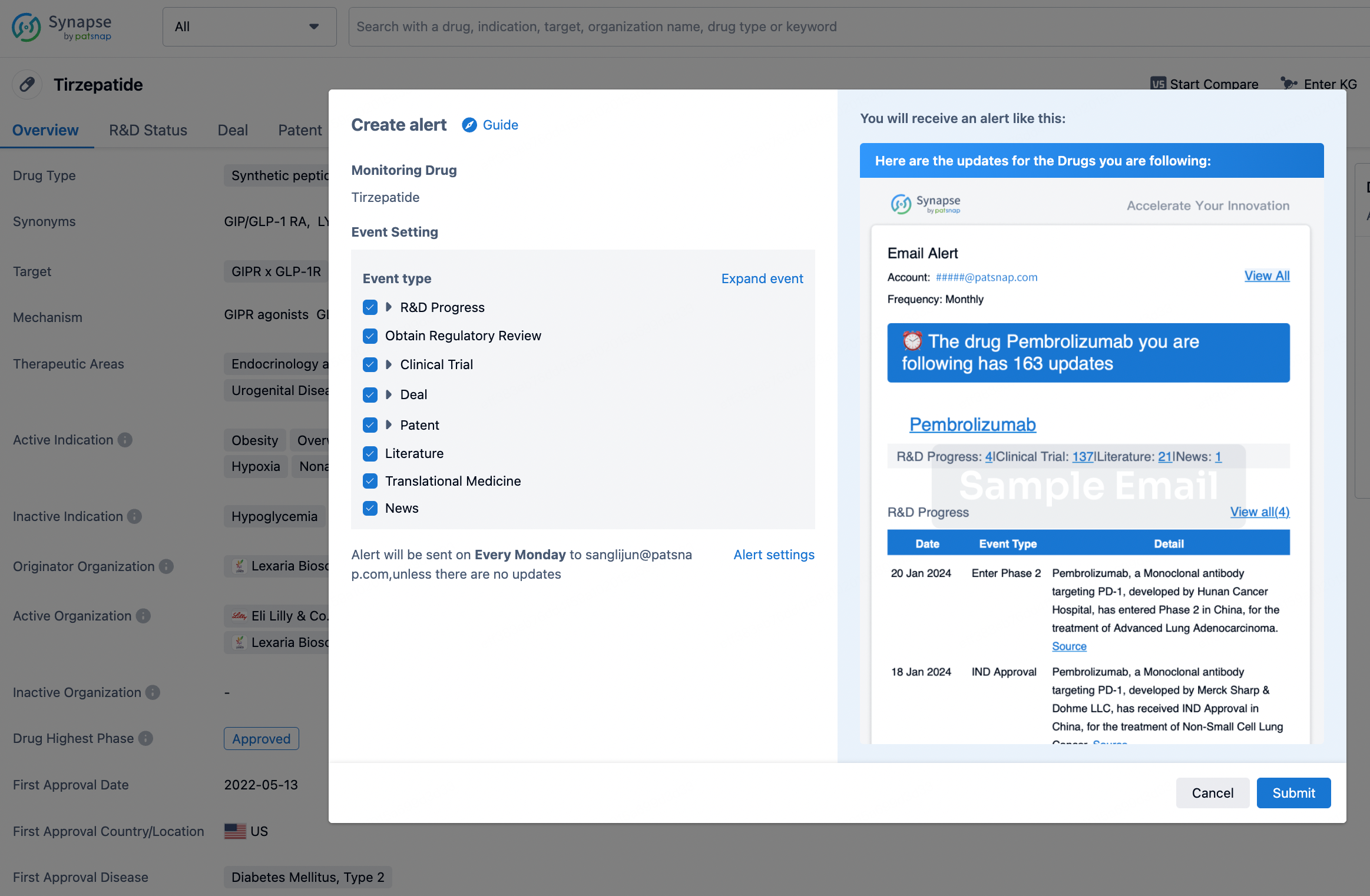
AI Agents Built for Biopharma Breakthroughs
Accelerate discovery. Empower decisions. Transform outcomes.
Get started for free today!
Accelerate Strategic R&D decision making with Synapse, PatSnap’s AI-powered Connected Innovation Intelligence Platform Built for Life Sciences Professionals.
Start your data trial now!
Synapse data is also accessible to external entities via APIs or data packages. Empower better decisions with the latest in pharmaceutical intelligence.